
HappyHorse is an AI video generation model developed by the ATH Innovation Center under Alibaba's Taotian Group. After version 1.0 launched in April 2026, it immediately climbed to the top two on the Artificial Analysis leaderboard — #1 on the no-audio chart with ELO 1357, tied for #1 on the with-audio chart at ELO 1212 alongside Seedance 2.0. Version 1.1 was released on June 22, alongside a global AI filmmaking competition.
Unlike Seedance and Kling, HappyHorse's core differentiator is its unified architecture — a single model processing text, image, video, and audio simultaneously. Not a modular pipeline stitched together, but a 15-billion-parameter single-stream Transformer generating everything in one pass.
What's New in 1.1 vs 1.0
| Dimension | 1.0 | 1.1 |
|---|---|---|
| Motion quality | Baseline | More natural, more physically plausible |
| Subject consistency | Occasional drift | Improved, more stable across scenes |
| Prompt following | Long prompts often went off track | Better adherence for complex multi-scene, multi-character prompts |
| Visual texture | Occasional oiliness, over-sharpening | Preserves realistic skin detail (pores, nasolabial folds) |
| Audio generation | Native sync | More natural pacing, pauses, and tone; prompt-driven ambient sound |
| Reference images | Up to 9 | Up to 9 (unchanged, but matching accuracy improved) |
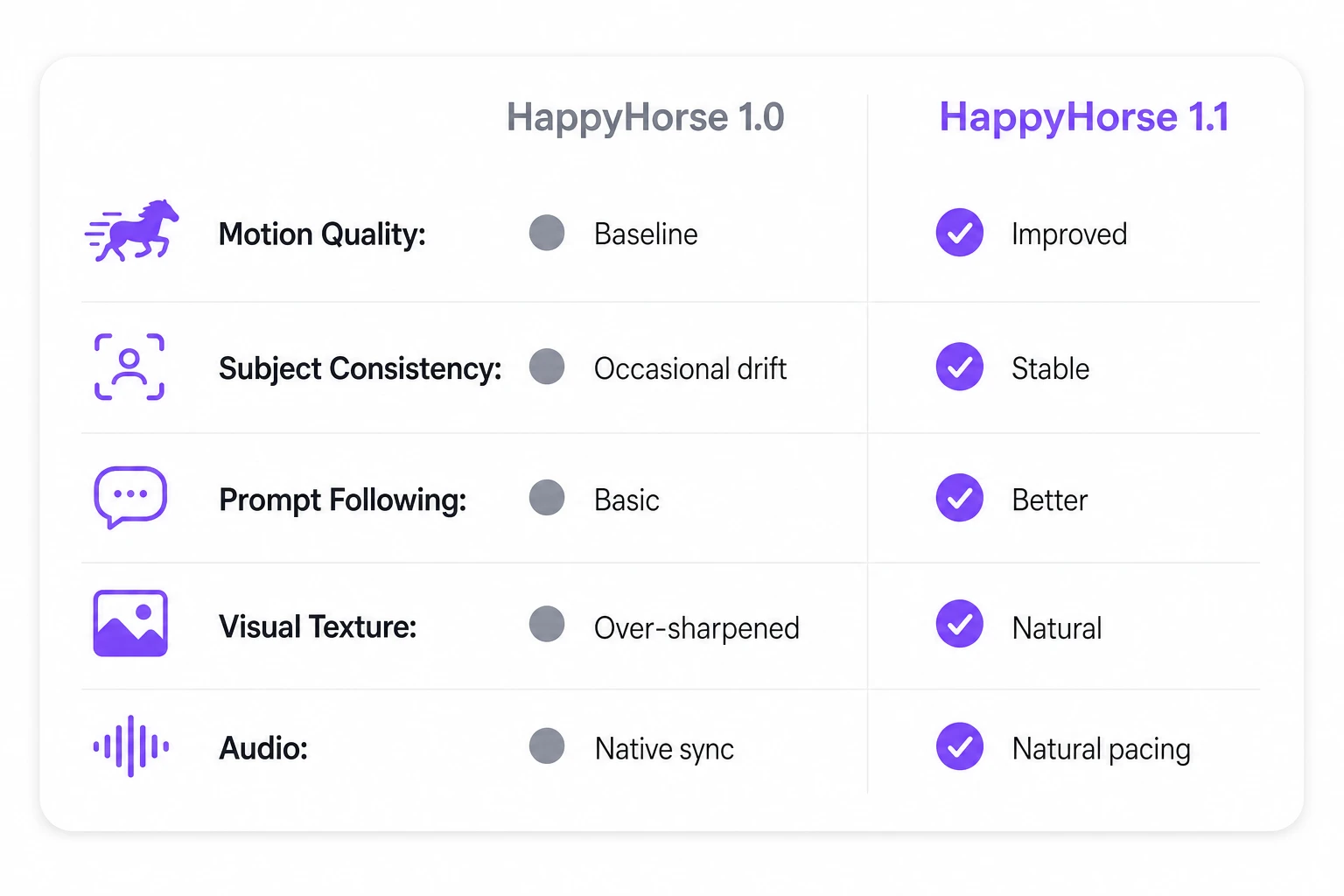
In short, 1.1 isn't a feature upgrade — it's a thorough polish. The issues users complained about in 1.0 — "oily look," "over-sharpened," "long prompts going off-track" — have been systematically addressed.
Key Specs
- Architecture: 15B-parameter unified single-stream Transformer, 40-layer self-attention, joint video + audio generation
- Resolution: Up to 1080P
- Duration: Up to 10 seconds
- Reference image input: Up to 9 images (R2V mode, tagged as character1, character2, etc. in prompts)
- Lip sync: 7 languages (Mandarin, Cantonese, English, Japanese, Korean, German, French)
- Aspect ratios: 16:9, 9:16, 1:1
R2V: How to Use 9 Reference Images
HappyHorse's Reference-to-Video (R2V) is what sets it apart from competitors. Upload up to 9 reference images, tag them as character1, character2, etc., and the model fuses each character's appearance, wardrobe, and style into the generated video.
Good use cases:
- Brand videos: Upload brand color palette + logo + product shots to maintain brand consistency
- Multi-character narratives: One reference image per character, maintaining individual appearances across shots
- IP adaptations: Upload character design sheets to generate that character in motion
For comparison: Seedance 2.0 supports 12 reference inputs (images + audio + video), and Seedance 2.5 expands that to 50. HappyHorse's 9-image cap is lower, but the tagging system makes multi-character scenes more intuitive to control.
Pricing
HappyHorse pricing varies by platform (as of June 2026):
| Platform | 720P per second | 1080P per second | Free credits |
|---|---|---|---|
| fal.ai (official API partner) | ~$0.18 | ~$0.32 | Yes |
| EvoLink | ~$0.18 | ~$0.32 | Free credits on signup |
| Alibaba Cloud Bailian | Not publicly disclosed | Not publicly disclosed | Yes |
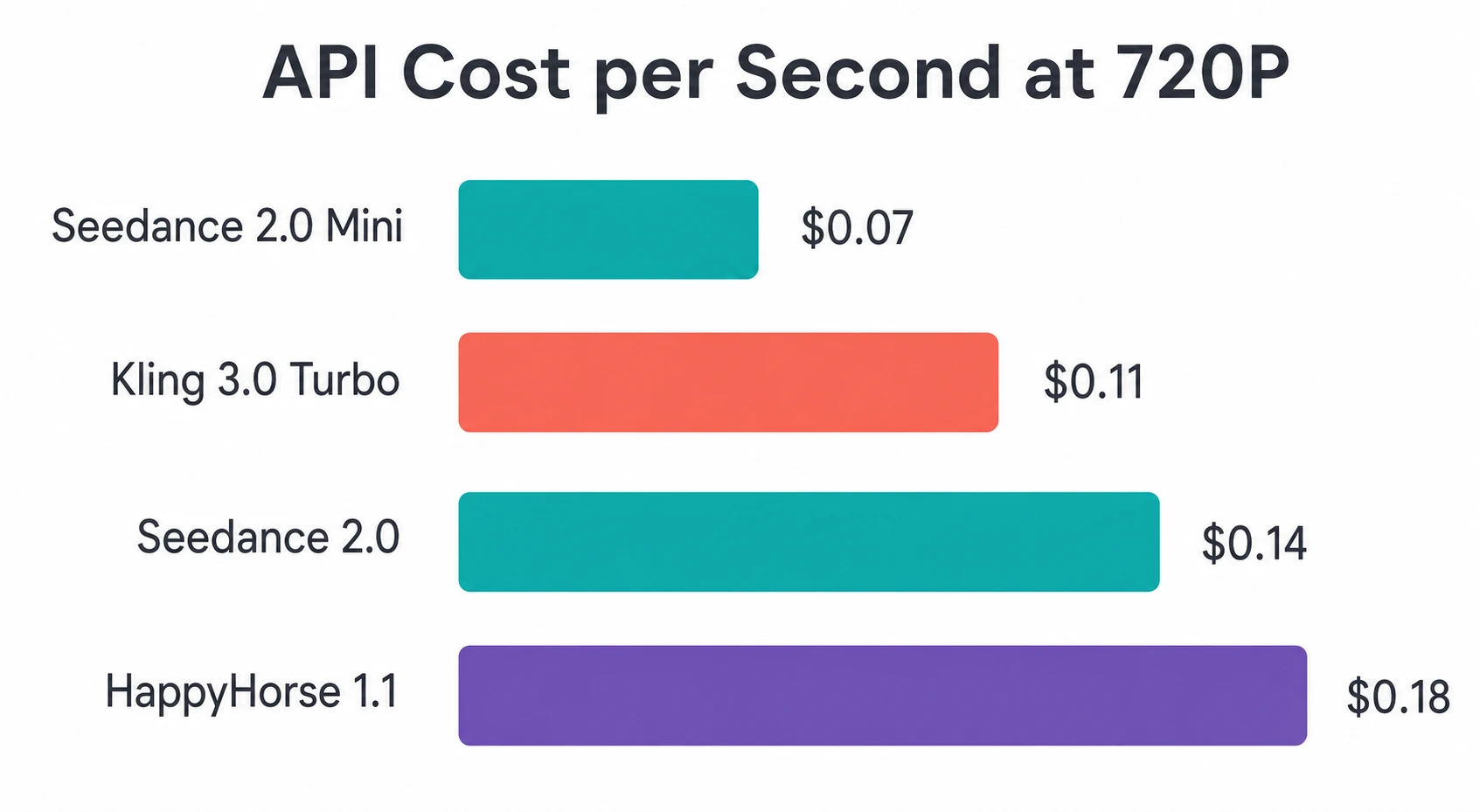
Compared to competitors: HappyHorse's API price ($0.18/sec at 720P) is higher than Seedance 2.0 Mini ($0.07/sec) and Kling 3.0 Turbo (~$0.11/sec), but its quality ranking is also higher.
How It Stacks Up Against Other Models
| Model | ELO ranking | Max resolution | Max duration | Audio | Reference inputs | Cost per second |
|---|---|---|---|---|---|---|
| HappyHorse 1.1 | #1-2 | 1080P | 10s | Native, 7 languages | 9 images | ~$0.18 |
| Seedance 2.0 | #1-2 | 4K | 15s | Native | 12 inputs | ~$0.14 |
| Kling 3.0 | #3 | 4K/60fps | 15s | Native + extra cost | Element system | ~$0.11 |
| Runway Gen-4 | #4-5 | 1080P | 10s | No native audio | Limited | ~$0.25 |
HappyHorse's strengths lie in quality rankings and 7-language lip sync. Its weaknesses are resolution (no 4K), duration (10 seconds vs competitors' 15), and price.
Verdict
HappyHorse 1.1 is one of the highest-ranked AI video models by ELO, and its 15-billion-parameter unified architecture delivers genuinely strong audio-visual coherence. But it's not a catch-all — the 10-second duration cap and 1080P resolution ceiling mean longer clips or 4K work still calls for Seedance or Kling.
Recommendations:
- Quality first, 7-language lip sync → HappyHorse 1.1
- Value and longer clips → Seedance 2.0 Mini or Kling 3.0 Turbo
- 4K, 30-second narratives → Seedance 2.5 (launching July)